
Codename Narwhal is Obama secret data integration project which started 9 months has paid off. The team of data scientists , developers, and digital advertising experts, putting there heads together to really get big data to help the team make better decision.
4Gb/s, 10k requests per second, 2,000 nodes, 3 datacenters, 180TB and 8.5 billion requests. Design, deploy, dismantle in 583 days to elect the President…
Key Take Away
While the entire platform is built on Amazon, its a greatly proven architecture, a lot of the application were build around the start up strategy “the open source culture” and the “idea of core Platform Services in the form of Narwhal Services” has made the overall picture very simple.
Background
At a very high level Narwhal integrated data across multiple applications
- Facebook,
- National list of voters and lot more data from the swing state.
- Swing state data : As a standard sales principle the 60% of customer who are on the fence are to be targeted well.
- Public voting records
- Responses coming directly from the voters
- Tracking voters across the web
- Serving ads to public with targeted messages on the campaign sites
- Analysing what does a voter read online
- Obama supporter on Facebook – cross sell sending emails to a supported about there friends in the swing states encouraging them to vote.
The starting of the data architecture was the database of registered voters from Democratic National Committee & keeping it up to date. Playing around with this data in terms of adding voter data mix seeing the trends.
Data collection has been highly private and running analysis this data to decide next probable strategies.
High Level Analytics
If we look into the Analytics -The Obama campaign had a list of every registered voter in the battleground states. The job of the campaign’s much-heralded data scientists was to use the information they had amassed to determine which voters the campaign should target— and what each voter needed to hear.
What did the data help them in
Deep Targeting of voters
Race wise targeting example Latino community using diversity
The data scientist really came down to the following Individual estimates for each swing state voter’s behaviour.
- These four numbers were included in the campaign’s voter database, and each score, typically on a scale of 1 to 100, predicted a different element of how that voter was likely to behave.
- Two of the numbers calculated voters’ likelihood of supporting Obama, and of actually showing up to the polls. These estimates had been used in 2008. But the analysts also used data about individual voters to make new, more complicated predictions.
- If a voter supported Obama, but didn’t vote regularly, how likely was he or she to respond to the campaign’s reminders to get to the polls?
The final estimate was the one that had proved most elusive to earlier campaigns—and that may be most influential in the future.
Micro targeting another numerical scoring mechanism is been used widely so more data on the same is here.
The Complete Architecture

The central piece or key application block is Amazon's cloud computing services for computing and storage power. At its peak, the IT infrastructure for the Obama campaign took up "a significant amount of resources in AWS's Northern Virginia data center,".
Narwhal Services
The key architectural decision marking in an ambiguous architecture situation is to get the core perfect. The Obama team build the core Narwhal a set of services that acted as an interface to a shared data stores for all application. Moreover the service layer was REST based which allowed building applications in any development language and platform making it possible to quickly develop new applications and to integrate existing ones into the campaign's system. Those apps include sophisticated analytics programs like Dreamcatcher, a tool developed to "microtarget" voters based on sentiments within text. And there's Dashboard, the "virtual field office" application that helped volunteers communicate and collaborate.
With introduction of Narwhal Services Layer this gave the option decoupling all application and allow each application scale up individually and at the same time allow to share data across all application. Given the nature of the business and the need to build the application on the fly it was important to build something like a Narwhal Services Layers
Platform Agnostic Development
With all services exposed as REST Based the option for developers to build an application in any language and platform.
The team
The idea of recruiting people who already knew the territory, snapping up both local talent and people from out of town with Internet bona fides—veterans from companies like Google, Facebook, Twitter, and TripIt.
"All these guys have had experience working in startups and experience in scaling apps from nothing to huge in really tight situations like we were in the campaign,".
The need to hire engineers who understand APIs—engineers that spend a lot of time on the Internet building platforms.
The Technical Stack
Narwhal. Written in Python, the API side of Narwhal exposes data elements through standard HTTP requests. While it was designed to work on top of any data store, the Obama tech team relied on Amazon's MySQL-based Relational Database Service (RDS). The "snapshot" capability of RDS allowed images of databases to be dumped into Simple Storage Service (S3) instances without having to run backups.
Even with the rapidly growing sets of shared data, the Obama tech team was able to stick with RDS for the entire campaign—though it required some finesse.
They were some limitations with RDS but they were largely self-inflicted . They were able to work around those and stretch how far we were able to take RDS. If the campaign had been longer, it would have definitely had to migrate to big EC2 boxes with MySQL on them instead."
The team also tested Amazon's DynamoDB "NoSQL" database when it was introduced. While it didn't replace the SQL-based RDS service as Narwhal's data store, it was pressed into service for some of the other parts of the campaign's infrastructure. In particular, it was used in conjunction with the campaign's social networking "get-out-the-vote" efforts.
The integration element of Narwhal was built largely using programs that run off Amazon's Simple Queue Service (SQS). It pulled in streams of data from NGP VAN's and Blue State Digital's applications, polling data providers, and many more, and handed them off to worker applications—which in turn stuffed the data into SQS queues for processing and conversion from the vendors' APIs. Another element of Narwhal that used SQS was its e-mail infrastructure for applications, using worker applications to process e-mails, storing them in S3 to pass them in bulk from one stage of handling to another.
Initially, Narwhal development was shared across all the engineers. As the team grew near the beginning of 2012, however, Narwhal development was broken into two groups—an API team that developed the interfaces required for the applications being developed in-house by the campaign, and an integration team that handled connecting the data streams from vendors' applications.
The applications
As the team supporting Narwhal grew, the pace of application development accelerated as well, with more applications being put in the hands of the field force. Perhaps the most visible of those applications to the people on the front lines were Dashboard and Call Tool.
Written in Rails, Dashboard was launched in early 2012. "It's a little unconventional in that it never talks to a database directly—just to Narwhal through the API," Ecker said. "We set out to build this online field office so that it would let people organize into groups and teams in local neighbourhoods, and have message boards and join constituency groups."
An Obama campaign video demonstrating how to use Dashboard.
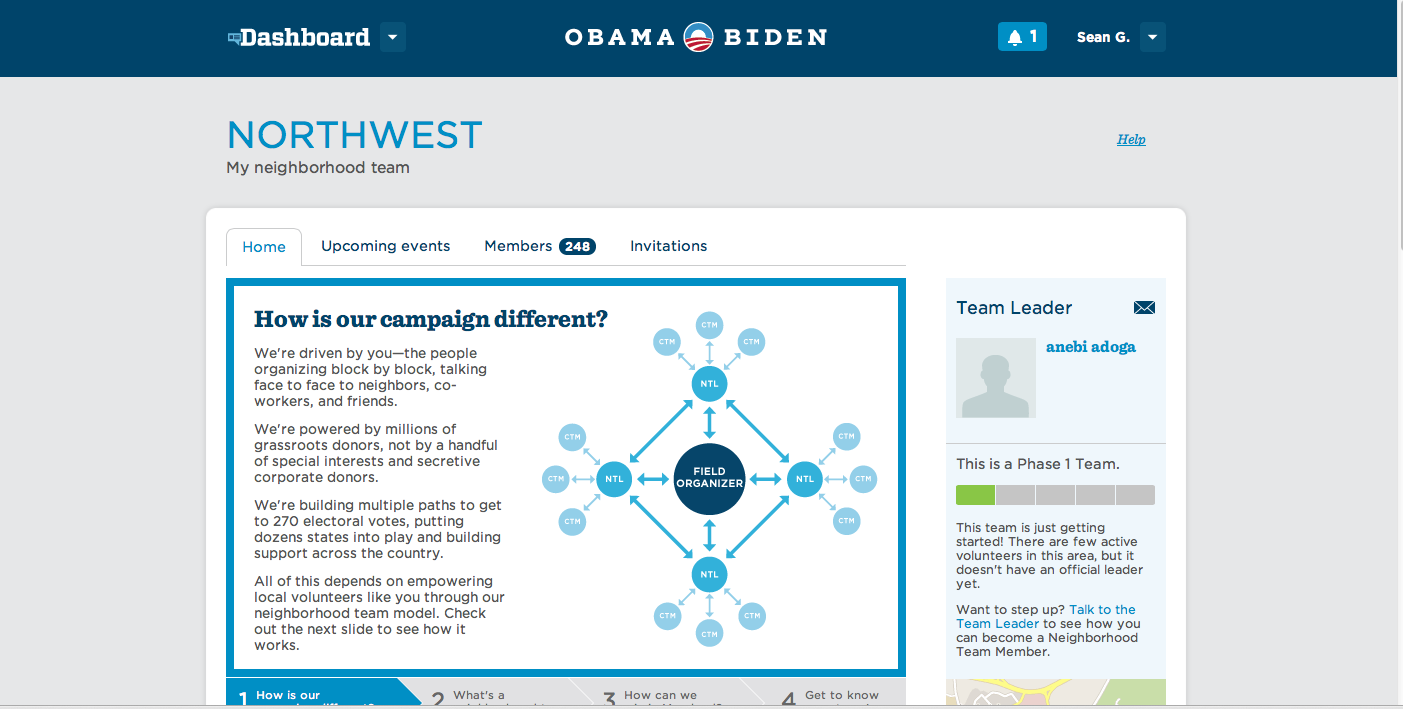
Enlarge / The Dashboard Web application, still live, helped automate the recruitment and outreach to would-be Obama campaign volunteers.
Dashboard didn't replace real-world field offices; rather, it was designed to overcome the problems posed by the absence of a common tool set in the 2008 election, making it easier for volunteers to be recruited and connected with people in their area. It also handled some of the metrics of running a field organization by tracking activities such as canvassing, voter registration, and phone calls to voters.
The Obama campaign couldn't mandate Dashboard's use. But the developer team evolved the program as it developed relationships with people in the field, and Dashboard use started to pick up steam. Part of what drove adoption of Dashboard was its heavy social networking element, which made it a sort of Facebook for Obama supporters.
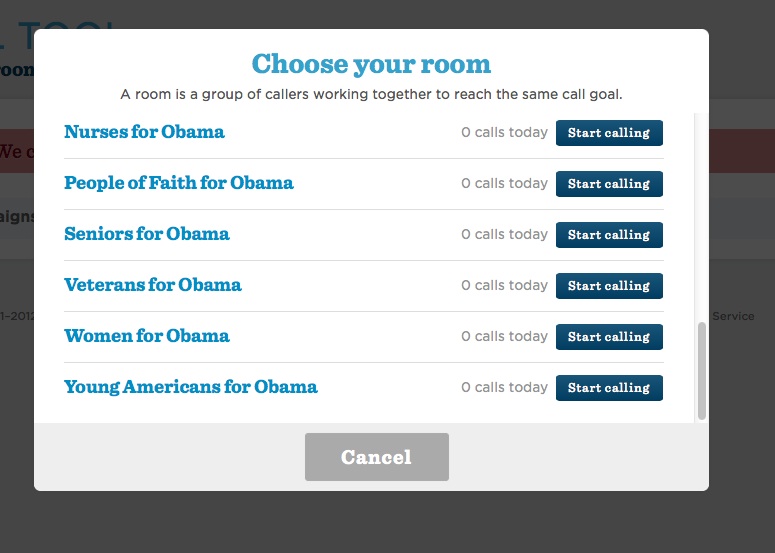
Enlarge / Call Tool offered supporters a way to join in on specific affinity-group calling programs.
Call Tool was the Obama campaign's tool to drive its get-out-the-vote (GOTV) and other voter contact efforts. It allowed volunteers anywhere to join a call campaign, presenting a random person's phone number and a script with prompts to follow. Call Tool also allowed for users to enter notes about calls that could be processed by "collaborative filtering" on the back end—identifying if a number was bad, or if the person at that number spoke only Spanish, for instance—to ensure that future calls were handled properly.
Both Call Tool and Dashboard—as well as nearly all of the other volunteer-facing applications coded by the Obama campaign's IT team—integrated with another application called Identity. Identity was a single-sign-on application that tracked volunteer activity across various activities and allowed for all sorts of campaign metrics, such as tracking the number of calls made with Call Tool and displaying them in Dashboard as part of group "leaderboards." The leaderboards were developed to "gamify" activities like calling, allowing for what Ecker called "friendly competition" within groups or regions.
All of the data collected through various volunteer interactions and other outreach found its way into Narwhal's data store, where it could be mined for other purposes. Much of the data was streamed into Dreamcatcher and into a Vertica columnar database cluster used by the analytics team for deep dives into the data.
A good comparison http://communities-dominate.blogs.com/brands/2012/11/orca-meets-narwhal-how-the-obama-ground-game-crushed-romney-a-look-behind-the-math.html
Solving real business problems with Cloud………………. Just the beginning

