
My earlier post on Architecting the Private Cloud shed light on real life scenario based on some of the customers experiences on what to ask, what are the steps on moving into Private Cloud and an example on mapping the services to cloud attributes. In the cloud we are governed by the cloud attributes to a large extent. In this post I want to take a dig into “what dwells into an average developer or architects mind on moving an on premise application on to the cloud”. The cloud can be private or public doesn’t matter , the assumption the private cloud architecture is in line with earlier post holds here.
What am addressing is post is “What are the software pattern & frameworks that are emerging in the cloud scenario” & What do customers do in practice.
As the new technologies come in they challenge some of the existing thinking, pattern way of writing of software. In the pre cloud world a standard distributed application breathed the following
- Synchronous: Does Request/ Response ring a bell, not far long ago in the web world this was a standard defacto and everyone just loved programming around this pattern.
- Dependency
- Tightly coupled architecture
- Asynchronous
- Independent Layers
- Loosely coupled architecture
So what’s happening differently here is “Asynchronous nature” the programming paradigm is becoming a standard for Windows 8.
In the past we had the Presentation Layer which is tightly coupled to the Business Layer, a lot of the architecture guidance has been around moving this to a true n- tier architecture which involved decoupling the Presentation and the Business Layer by introducing a Services Layer & decoupling the Business/ Data Layers using something like ORM. Essentially this is horizontal decoupling. Most of our current day applications exists in this form.
The question really boils down “Is this architecture good enough for cloud?”
How can be this taken to a cloud deployment may amazon (aws) or windows azure so evidently this is what it looks like

Depending on the nature of technology you can choose any 1 of them, the above is an Amazon stack. At high level the amazon application architecture would look like something below.
In Azure the presentation layer would be assigned to a web role and business/application tier would get into worker role. The database would be a standard sql azure or a blob. In case of amazon the presentation and application would be running on something what the call is the elastic bean stalk which is similar to web and worker role combined & database
- RDS – Relational Storage Service
- Simple DB
- S3 – Blob

Above is a visual representation on Windows Azure Deployment
The above architecture can scale out with more web or worker role this currently works on the cloud but there is a reason as why do we have to relook at this architecture.
The Problem Statement Defined…
“In the above architecture when it comes to presenting or distributing information the multiple viewers its not easy to scale that read portion of the solution without affecting the write portion of the solution so you have the inserts, updates & reads this is an overhead there is a need to isolate the read from writes”. There’s needs to be a segregated IO channel for both reads & writes. Typically in write there will be record locking.
This is not new we have seen architectural solution something like ORM which introduces a cache which kind reducing the read latency for the overall application at the cost of memory. The caching mechanism in most scenarios is an after thought.
As always there will be new ways to solve the issue they new term here is CQRS (Command Query Response Segregation)
Command Query Response Segregation to your Rescue….
CQRS first surfaced by Greg Young a complete post is available by Martin Fowler.Getting the Basics on CQRS
The problem statement from an architectural stand point of view is to segregate the the Reads from the Writes , so at a very simplistic level a notion that you can use a different model to update information than the model you use to read information.
We are used to the idea of thinking of CRUD as a single datastore for interaction purpose.. By this I mean that we have mental model of some record structure where we can create new records, read records, update existing records, and delete records when we're done with them. In the simplest case, our interactions are all about storing and retrieving these records.
The needs to todays are more sophisticated the need to look at the information in a different way to the record store, perhaps collapsing multiple records into one, or forming virtual records by combining information for different places. On the update side we may find validation rules that only allow certain combinations of data to be stored, or may even infer data to be stored that's different from that we provide.
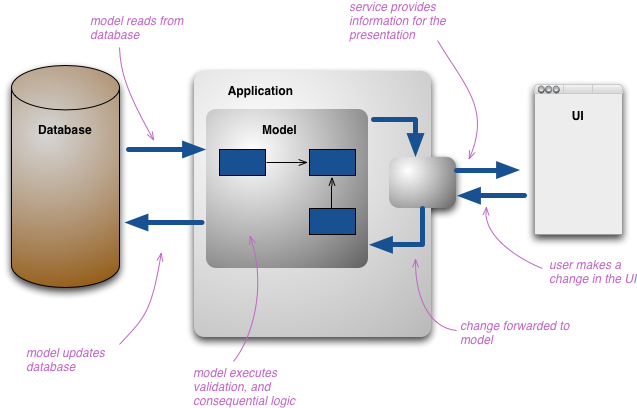
Since the information request is so varied there is need to have multiple representation of the same information, When users interact with the information they use various presentations of this information, each of which is a different representation. Developers typically build their own conceptual model which they use to manipulate the core elements of the model. If you're using a Domain Model, then this is usually the conceptual representation of the domain. You typically also make the persistent storage as close to the conceptual model as you can.
This structure of multiple layers of representation can get quite complicated, but when people do this they still resolve it down to a single conceptual representation which acts as a conceptual integration point between all the presentations.
The change that CQRS introduces is to split that conceptual model into separate models for update and display, which it refers to as Command and Query respectively following the vocabulary of CommandQuerySeparation. The rationale is that for many problems, particularly in more complicated domains, having the same conceptual model for commands and queries leads to a more complex model that does neither well.
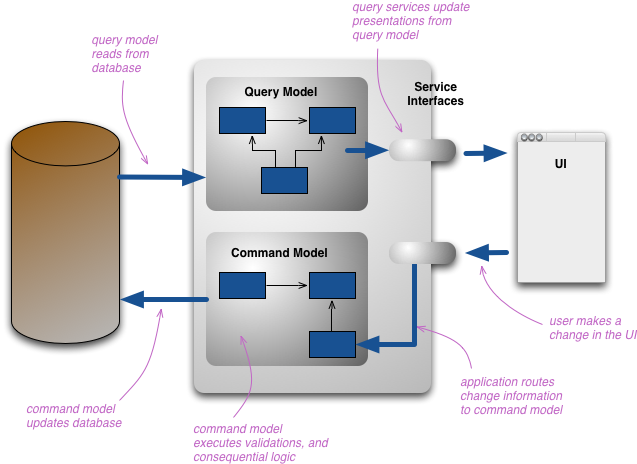
By separate models we most commonly mean different object models, probably running in different logical processes, perhaps on separate hardware. A web example would see a user looking at a web page that's rendered using the query model. If they initiate a change that change is routed to the separate command model for processing, the resulting change is communicated to the query model to render the updated state.
Write Operations become Commands are put in a queue , Read Operations are essentially queries.
CQRS as a concept is a set of principles, a way of thinking about software architecture
As a Pattern it is a way of designing & developing scalable , robust enterprise solutions where reads are independent from the writes.
Benefits of CQRS
- Scalability: Ability to increase or reduce the number of resources without affecting the end user experience.
- Speed: Faster delivery of information is crucial
- Reduced Complexity: Improved Maintainability.
CQRS & the data stores story…
With the read and write separation the data store implementation can be many- Can have separate data store for read (on cloud) & write on premises and replicate back to the on cloud read data store.
- Can have the same data store with 2 different object models.
- Can have the same data store with same object models implementing the query & command interfaces
How Does CQRS really solve our Big Problem Statement..
Coming back the architecture n tier architecture in cloud and how does CQRS address it
The CQRS implementation has below is a conceptual understanding
- When users ends up doing some operation that operation becomes a command, that command is stored in the command queue,
- There some kind of background process typically a worker role & the command handler is running in that process the command handler is looking in queue of commands and individually processing them when its finished processing them it will take them and raise an event that typically ends up in an event queue.
- At the very same moment there may be a dispatcher running. The dispatcher is also known as an event processor and its looking at the events queue and processing them and dispatching them as a bunch of readable data stores and the readers have the data in the format
From a CQRS there are some other patterns which are required to support the overall construct below are the same.
Domain Driven Design (DDD)
The Command and Query end up functioning on a Object Model. From an implementation stand point of view they can have different object models or same doesn’t really matter, the intend has to be the object model very similar to the persistent model.The model can be based on a complex domain design. The focus of any model has be on the domain and domain logic and be technology agnostic to a large extent.
Event Sourcing
Cloud Application have to follow the asynchronous pattern. Given that we are in a disconnected , stateless world we need to use some mechanism to communicate between components event sourcing becomes an alternate for the same. Event sourcing is a simple concept its like storing all the user actions and storing it as a time sequential list.- Captures all changes to an application state as a sequence of events.
- Allows developers to determine how much much a given state has reached
- Also allows developers to reconstruct past states
We can query an application's state to find out the current state of the world, and this answers many questions. However there are times when we don't just want to see where we are, we also want to know how we got there.
Event Sourcing ensures that all changes to application state are stored as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.
The key to Event Sourcing is that we guarantee that all changes to the domain objects are initiated by the event objects. This leads to a number of facilities that can be built on top of the event log:
- Complete Rebuild: We can discard the application state completely and rebuild it by re-running the events from the event log on an empty application.
- Temporal Query: We can determine the application state at any point in time. Notionally we do this by starting with a blank state and rerunning the events up to a particular time or event. We can take this further by considering multiple time-lines (analogous to branching in a version control system).
- Event Replay: If we find a past event was incorrect, we can compute the consequences by reversing it and later events and then replaying the new event and later events. (Or indeed by throwing away the application state and replaying all events with the correct event in sequence.) The same technique can handle events received in the wrong sequence - a common problem with systems that communicate with asynchronous messaging
Cloud Scenario #1 – Important concepts of the Cloud are Scalable & Elasticity, the requirement really boils down to application built in terms of components and baked into a service unit. These service unit have a SLA, service units can be a conceptual lines business application or functional module which has to be stateless. A hypothetical situation could be the fabric controller is running an optimization algorithm and decides to shoot down your running applications and rebuild it on another instance Event Sourcing is something which is much needed here to do a complete rebuild.
Structuring the Event Handler Logic
There are a number of choices about where to put the logic for handling events. The primary choice is whether to put the logic in Transaction Scripts or Domain Model. As usual Transaction Scripts are better for simple logic and a Domain Model is better when things get more complicated.In general I have noticed a tendency to use Transaction Scripts with applications that drive changes through events or commands. Indeed some people believe that this is a necessary way of structuring systems that are driven this way. This is, however, an illusion.
A good way to think of this is that there are two responsibilities involved. Processing domain logic is the business logic that manipulates the application. Processing selection logic is the logic that chooses which chunk of processing domain logic should run depending on the incoming event. You can combine these together, essentially this is the Transaction Script approach, but you can also separate them by putting the processing selection logic in the event processing system, and it calls a method in the domain model that contains the processing domain logic.
Once you've made that decision, the next is whether to put the processing selection logic in the event object itself, or have a separate event processor object. The problem with the processor is that it necessarily runs different logic depending on the type of event, which is the kind of type switch that is abhorrent to any good OOer. All things being equal you want the processing selection logic in the event itself, since that's the thing that varies with the type of event.
Of course all things aren't always equal. One case where having a separate processor can make sense is when the event object is a DTO which is serialized and de-serialized by some automatic means that prohibits putting code into the event. In this case you need to find selection logic for the event. My inclination would be to avoid this if at all possible, if you can't then treat the DTO as an hidden data holder for the event and still treat the event as a regular polymorphic object. In this case it's worth doing something moderately clever to match the serialized event DTOs to the actual events using configuration files or (better) naming conventions.
Challenges with CQRS
- Separating Reads from Writes introduce challenges
- Data Staleness need special handling
- CQRS doesn’t consider staleness as an exceptional cases, its expected
- CQRS does not use record locking mechanism
* The SLA of having data staleness down near zero is something which will drive a lot of design decisions ex: banking applications.Probable Solutions for Data Staleness in CQRS
Eventual Synchronization of any primary data repository and any caching mechanism must be guaranteed.
- Processing of command changes to the primary data storage mechanism and events publishing should be performed transactionally together.
- If using a message bus this can be achieved by using transactional queues.
Some the frameworks on CQRS…
Lockad.CQRS – Get the binaries here - https://github.com/lokad/lokad-cqrs/ based on .NET meant for Windows Azure- Managing of message contracts, serialization formats, and transport envelopes
- Sending messages to supported queues: In memory and Azure queues
- Message scheduling for the delayed delivery of messages to the recipients
- Message routing for implementing load balancing and partitioning
Ncqrs – Main features find the binaries here - http://ncqrs.org/
- Command handling, including servicing & execution
- Event Sourcing support
- Domain modeling support
- Additional support for
- NServiceBus
- SQLite
- StructureMap
- RavenDB
- Google Groups - http://groups.google.com/group/dddcqrs
- Microsoft Pattern & Practice is planning to get something out.
No comments:
Post a Comment